6.9 KiB
Отчёт. Задание 1 - структуры данных
Цель
Реализовать три структуры данных (связный список, хеш-таблица, BST) и экспериментально сравнить их производительность на операциях insert / find / delete при случайном и отсортированном порядке входных данных.
Параметры эксперимента
| Параметр | Значение |
|---|---|
| N (записей) | 10 000 |
| Повторений | 5 |
| Поисков | 100 существующих + 10 несуществующих |
| Удалений | 50 |
Результаты
Случайные данные (shuffled)

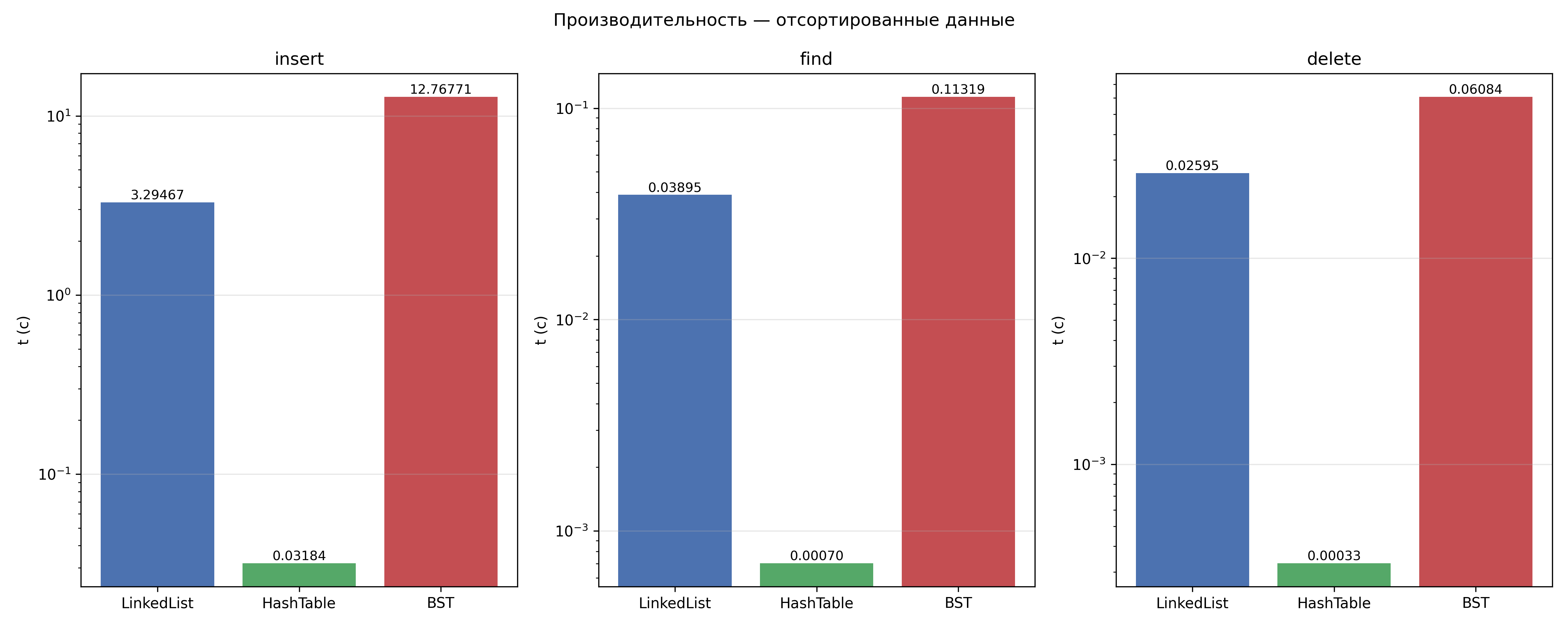
Отсортированные данные (sorted)
Анализ
Деградация BST на отсортированных данных
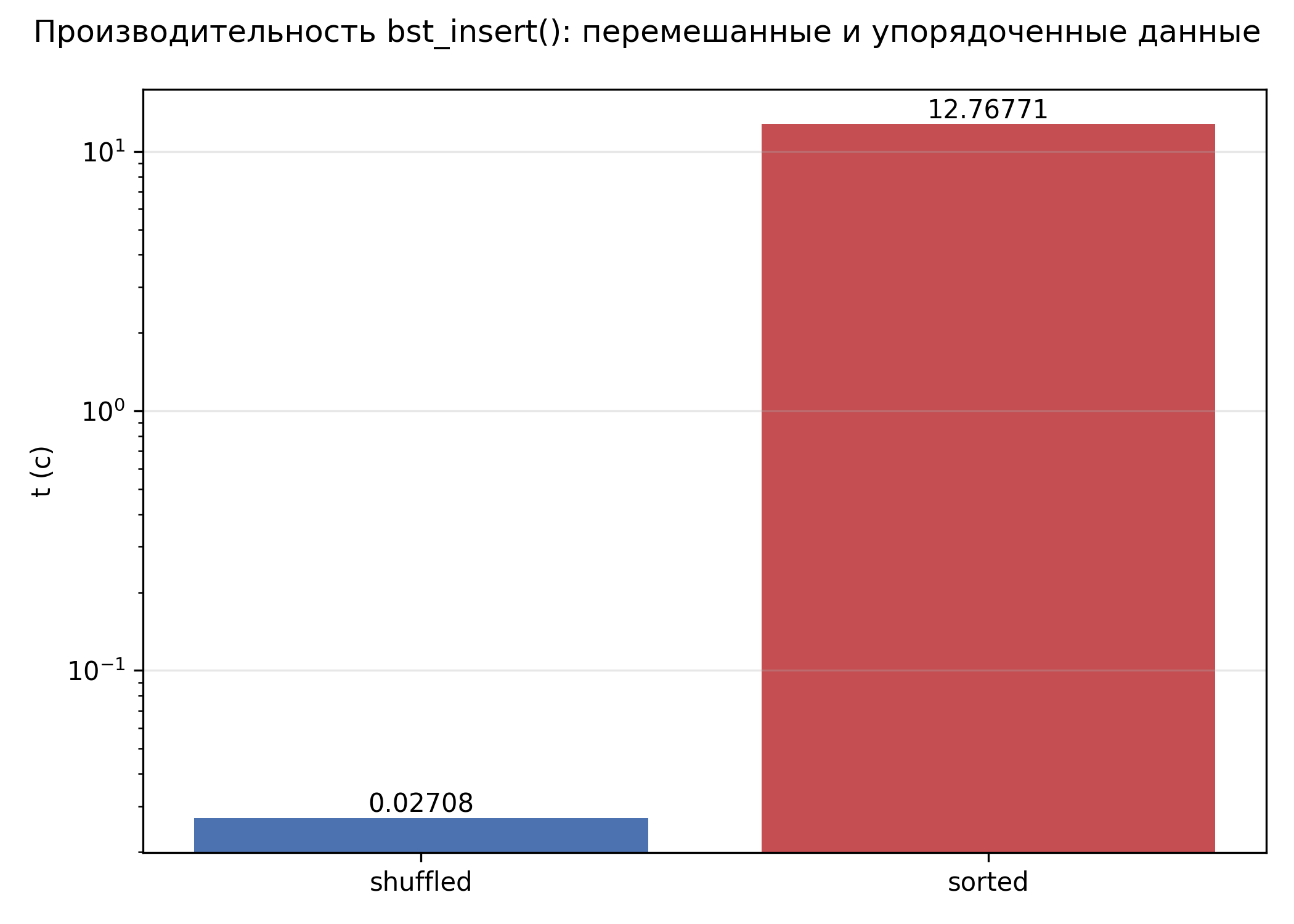
На случайных данных BST - самая быстрая структура: insert 0.027 с. Случайный порядок вставки даёт сбалансированное дерево глубиной ~log N, поэтому каждый новый узел находит своё место за O(log N) шагов. На отсортированных - 12.77 с, то есть в ~473 раз медленнее. Причина: при последовательной вставке отсортированных ключей каждый новый узел уходит в правое поддерево предыдущего. Дерево вырождается в цепочку глубиной N, и каждая вставка требует O(N) шагов вместо O(log N).
Хеш-таблица нечувствительна к порядку
HashTable показывает практически одинаковое время в обоих режимах (insert: 0.033 с против 0.032 с). Это ожидаемо:
индекс бакета вычисляется через hash(name), который не зависит от порядка вставки. Операции работают за O(1)
при любом входе.
Связный список медленен при поиске
LinkedList не имеет никакой структуры для навигации - единственный способ найти запись это пройти список от головы до нужного узла. Find всегда O(N) независимо от порядка данных: shuffled 0.041 с, sorted 0.039 с. Insert O(N^2) для всей выборки - перед каждой вставкой нужно пройти весь список для проверки дубликата. На отсортированных данных LinkedList не меняет поведение, тогда как BST деградирует до 12.77 с - в этом единственном сценарии LinkedList оказывается быстрее BST.
Удаление
LinkedList - чтобы удалить узел, нужно пройти список от головы до нужного элемента и перешить next предшественника. Это O(N) в любом случае, порядок данных не имеет значения. Shuffled: 0.027 с, sorted: 0.026 с - разница в пределах погрешности.
HashTable - вычисляем индекс бакета через hash(name), затем удаляем узел из связного списка этого бакета. Порядок вставки не
влияет на то, в каком бакете лежит запись, поэтому время стабильно в обоих режимах: 0.00033 с.
BST - ищем узел спуском по дереву, затем обрабатываем три случая: нет потомков, один потомок, два потомка. На случайных данных дерево сбалансировано, глубина ~log N, удаление занимает 0.00014 с. На отсортированных данных дерево вырождено в цепочку - каждый узел уходил в правое поддерево при вставке, поэтому поиск удаляемого узла проходит через всю цепочку O(N). Результат: 0.061 с, то есть в ~435 раз медленнее.
Вывод
Частые вставки - HashTable. Время вставки не зависит от порядка и объёма данных: индекс бакета вычисляется за O(1), вставка в бакет - тоже O(1). Подтверждают цифры: 0.033 с на shuffled и 0.032 с на sorted при N=10000.
Частый поиск - HashTable. По той же причине: hash(name) сразу указывает на нужный бакет, линейный перебор не нужен.
Find: 0.00057 с на shuffled, 0.00070 с на sorted - стабильно при любом входе.
Получить данные в отсортированном порядке - BST при случайном порядке вставки. Элементы размещаются по правилу BST (слева меньшие корня, справа большие корня), поэтому обход по схеме левое поддерево -> корень -> правое поддерево возвращает все записи в алфавитном порядке без дополнительной сортировки. Важное условие: данные должны вставляться в случайном порядке, иначе дерево вырождается (см. деградацию BST на отсортированных данных).
LinkedList сам по себе проигрывает по всем операциям из-за O(N**2) на вставку и O(N) на поиск. Однако его идея лежит в основе хеш-таблицы: каждый бакет - это связный список, через который разрешаются коллизии. Как самостоятельная структура данных для справочника он неэффективен, но как строительный блок внутри HashTable - незаменим.